教机器人捏橡皮泥?MIT、IBM, UCSD等联合发布软体操作数据集

虚拟环境(ALE、MuJoCo、OpenAI Gym)极大地促进了在智能体控制和规划方面学习算法的发展和评估,然而现有的虚拟环境通常只涉及刚体动力学。尽管软体动力学在多个研究领域有着广泛的应用(例如,医疗护理中模拟虚拟手术、计算机图形学中模拟人形角色、机器人技术中开发仿生制动器、材料科学中分析断裂和撕裂),关于构建标准软体环境和基准的研究却很少。
与刚体动力学相比,软体动力学的模拟、控制和分析更加错综复杂。最大的挑战之一来自其无限的自由度(DoFs)和对应的高维控制方程。软体动力学的内在复杂性使许多为刚体设计的机器人算法无法直接应用,并抑制了用于评估软体任务算法的模拟基准的发展。
在一项近期研究中,MIT 沃森人工智能实验室首席科学家淦创团队与来自MIT, USCD等机构的研究者共同提出了一个支持梯度可导的机器人软体操作平台(PlasticineLab) 来解决这个问题。这篇论文内容在 ICLR 2021 大会上被选为spotlight。

论文地址:https://arxiv.org/pdf/2104.03311.pdf
项目链接:http://plasticinelab.csail.mit.edu/
Code 下载:https://github.com/hzaskywalker/PlasticineLab
该基准可用于运行和评估总共 10 种软体操作任务,这些任务包含 50 种配置,必须通过复杂的操作来执行,包括捏、滚、切、成型和雕刻。其特点在于模拟环境采用可微物理,并且首次为软体分析提供梯度信息,从而可以通过基于梯度的优化进行监督学习。在软体模型方面,我们选择了研究橡皮泥(图 1 左),这是一种用于雕刻的多功能弹塑性材料,在小变形下表现为弹性形变,在大变形下表现为塑性形变。与常规弹性软体相比,橡皮泥具有更加多样和真实的行为,并带来了先前研究中未探索的挑战,使其成为测试软体操作算法的代表性媒介(图 1 右)。

图 1 左:一个孩子用擀面杖将一块橡皮泥变形成薄饼。右:PlasticineLab 中具有挑战性的 RollingPin 场景。智能体需要通过来回滚动擀面杖,使橡皮泥变形为目标形状。
我们通过 Taichi 实现 PlasticineLab 的梯度支持和弹塑性材料模型,其 CUDA 后端采用 GPU 大规模并行来实时模拟各种 3D 软体。随后通过移动最小二乘材料点法和 von Mises 屈服准则对弹塑性材料进行建模,并利用 Taichi 的双尺度反向模式微分系统来自动计算梯度,包括塑性材料模型带来的具有数值挑战性的 SVD 梯度。具备完整的梯度后,我们在 PlasticineLab 中所有软体操作任务上评估了基于梯度的规划算法,并将其效率与基于强化学习的方法进行了比较。
实验表明,基于梯度的规划算法可以利用物理模型的额外知识在数十次迭代中找到更有价值的解决方案,而基于强化学习的方法即使在 1 万次迭代之后仍可能会失败。但是基于梯度的方法缺乏足够的动力来解决长期规划问题,尤其是在多阶段任务上。
这些发现加深了对基于强化学习和基于梯度的规划算法的理解。此外,它还提供了一个可能的研究方向,即融合这两种方法的优点来推进软体动力学复杂规划任务的发展。这项工作主要有以下几点贡献:
提出了首个涉及弹性和塑性软体的技能学习基准。
开发了一个功能齐全的可微物理引擎,它支持弹性和塑性变形、软刚性材料相互作用,以及可微的定制接触模型。
基准中广泛的任务覆盖范围能够对代表性基于强化学习和基于梯度的规划算法进行系统的评估和分析。我们希望该基准可以激发未来的研究,将可微物理和强化学习相结合。
我们还计划通过更多的关节系统来扩展基准测试,例如虚拟影子手。作为一种起源于计算物理界的原理性模拟方法,MPM 在细化下可收敛,并且具有自身的精度优势。建模错误在虚拟环境中不可避免,不过,模拟梯度信息除了作为规划的强大监督信号外,还可以指导系统识别。这可能使机器人学研究人员能够自己「优化」任务,与控制器优化同时进行,从而自动最小化模拟与真实之间的差距。PlasticineLab 可以显著降低未来软体操纵技能学习研究的障碍,并为机器学习社区做出独特贡献。
PLASTICINELAB 学习环境
PlasticineLab 包含由可微物理模拟器支持的具有挑战性的软体操作任务,其中的所有任务都需要智能体使用刚体操纵器将一块或多块 3D 橡皮泥变形。底层模拟器允许用户对软体执行复杂的操作,包括捏、滚、切、成型和雕刻。
任务描述
PlasticineLab 具有 10 种侧重于软体操作的任务。每个任务都包含一个或多个软体和一个操纵器,最终目标是通过规划操纵器的运动将软体变形为目标形状。智能体的设计遵循标准的强化学习框架,通过马尔可夫决策过程进行建模。每个任务的设计由其状态和观察、动作表征、目标定义以及奖励函数来定义。
马尔可夫决策过程
一般来说,马尔可夫决策过程包含状态空间、动作空间、奖励函数和转换函数。在 PlasticineLab 中,物理模拟器决定了状态之间的转换。智能体的目标是找到一个随机策略,根据给定状态对动作进行采样,从而最大化预期累积未来回报,其中为折扣因子。
״̬
任务的状态包括软体的正确表征和操纵器的末端执行器。我们遵循先前工作中广泛使用的基于粒子的模拟方法,将软体物体表示为一个粒子系统,其状态包括粒子的位置、速度以及应变和应力信息。具体来说,粒子状态被编码为大小为的矩阵,其中是粒子的数量。矩阵中的每一行都包含来自单个粒子的信息:两个表示位置和速度的 3D 向量,两个表示形变梯度和仿射速度场的 3D 矩阵,所有信息堆叠并压平为一个维向量。
作为运动学刚体,操纵器的末端执行器由 7D 向量表示,由 3D 位置和 4D 四元数方向组成,尽管在某些场景中可能会禁用某些自由度。对于每个任务,该表征会产生一个矩阵来编码操纵器的完整状态,其中为任务中所需的操纵器数量,为3或7,取决于操纵器是否需要旋转。关于软体和操纵器之间的交互,我们实现了刚体和软体之间的单向耦合,并固定了所有其他物理参数,例如粒子质量和操纵器摩擦力。
观察
虽然粒子状态完全表征了软体动力学,但其高自由度对于任何直接使用的规划和控制算法都难以处理。因此,我们下采样个粒子作为标识,并将它们的位置和速度(每个标识为 6D)叠加到大小为的矩阵中,用作粒子系统的观察。值得注意的是,同一任务中的标识在橡皮泥的初始配置中具有固定的相对位置,从而在任务的不同配置中实现一致的粒子观察。结合粒子观察和操纵器状态,我们最终得到的观察向量具有个元素。
动作
在每个时间步长,智能体以运动学的方式更新操纵器的线速度(必要时也包括角速度),得到大小为的动作,其中为3或6,取决于操纵器是否能否旋转。对于每个任务,我们提供全局,动作的下限和上限以稳定物理模拟。
目标和奖励
每个任务都具备一个由质量张量表示的目标形状,它本质上是将其密度场离散为大小为的规则网格。在每个时间步长t,我们计算当前软体的质量张量。将目标和当前形状离散为网格表示,便于我们通过比较相同位置的密度来定义它们的相似性,避免匹配粒子系统或点云的挑战性问题。奖励函数的完整定义包括一个相似性度量以及两个关于操纵器高层次运动的正则化器:
其中,为两个形状的质量张量之间的距离,为两个形状质量张量的带符号距离场的点积,鼓励操纵器靠近软体。对于所有任务,正权重都是常数。偏差确保每个环境最初的奖励为非负值。
评估组件
PlasticineLab 共包含 10 种不同的任务(图 2)。我们在这里描述了 4 个具有代表性的任务,其余 6 个任务在附录 B 中有详细说明。
这些任务及其不同配置下的变体形成了一套评估组件,用于对软体操作算法的性能进行基准测试。每个任务有 5 种变体(总共 50 种配置),通过扰动初始和目标形状以及操纵器的初始位置生成。

图 2 PlasticineLab 的任务和参考解决方案,其中某些任务需要多阶段规划。
Rope 智能体需要通过两个球形操纵器将一根长绳状橡皮泥缠绕在一根刚性柱子上。支柱的位置在不同的配置中有所不同。
Writer 智能体需要操纵一支「笔」(通过一个垂直胶囊表示),在立方橡皮泥上绘制目标涂鸦。对于每种配置,我们通过在橡皮泥表面上绘制随机 2D 线条来生成涂鸦。笔尖通过三维动作进行控制。
Chopsticks 智能体需要使用一双筷子(通过两个平行胶囊表示),拿起地上的长绳状橡皮泥并将其旋转到目标位置。操纵器具有 7 个自由度:6 个自由度用于移动和旋转筷子,1 个自由度用于控制每根筷子之间的距离。
RollingPin 智能体需要学习用刚性擀面杖压平「比萨面团」(通过立方橡皮泥表示)。我们通过具有 3 个自由度的胶囊模拟擀面杖:1)擀面杖可以垂直下降以按压面团;2)擀面杖可沿垂直轴旋转以改变其方向;3)智能体也可以将擀面杖在橡皮泥上滚动以将其压平。
可微弹塑性模拟
该模拟器通过 Taichi 实现并在 CUDA 上运行。连续介质力学通过移动最小二乘材料点法进行离散化,这是一种计算机图形学中相比 B 样条材料点法更简单、更有效的变体。模拟器中同时使用了拉格朗日粒子和欧拉背景网格。材料的属性包括位置、速度、质量、密度和形变梯度。这些属性存储在与材料一起移动的拉格朗日粒子上,而粒子与刚体的相互作用和碰撞在背景欧拉网格上处理。
在这里我们专注于材料模型的(可微分)可塑性扩展,作为橡皮泥的一个定义特征,利用 Taichi 的反向模式自动微分系统进行大多数梯度评估。
von Mises 屈服准则
遵循 Gao 等人的工作,我们使用简单的 von Mises 屈服准则来模拟塑性。根据 von Mises 屈服准则,橡皮泥粒子在其偏应力第二个不变量超过某个阈值时屈服(即塑性变形),并且由于材料「忘记「了其静止状态,因此需要对形变梯度进行投影。此过程在 MPM 文献中通常称为返回映射。
返回映射及其梯度
遵循 Klar 等人和 Gao 等人的工作,我们将返回映射实现为每个粒子形变梯度奇异值的 3D 投影过程。这意味着我们需要对粒子的形变梯度进行奇异值分解(SVD)过程,研究者在附录 A 中提供了该过程的伪代码。对于反向传播,需要评估 SVD 的梯度。Taichi 内部的 SVD 算法具有迭代性,当用蛮力的方式自动微分时,它的数值并不稳定。我们使用 Townsend 等人提出的方法来区分 SVD。对于奇异值不明显时分母为零的问题,遵循 Jiang 等人的方法促使分母的绝对值大于。
可微接触模型及其软体版本
遵循标准的 MPM 实现,使用库仑摩擦基于网格的接触处理来解决软体与地板和刚体障碍物 / 操纵者的碰撞。刚体表示为随时间变化的 SDFs。在经典的 MPM 中,接触处理会导致沿刚软边界的速度发生剧烈的非平滑变化。为了提高奖励平滑度和梯度质量,我们在反向传播过程中使用了软化接触模型。对于任何网格点,模拟器计算其到刚体的有符号距离。然后我们计算一个平滑碰撞强度因子,当逐步衰减到 0 时,该因子呈指数增加。直观来说,当刚体靠近网格点时,碰撞效果会变得更强。正参数决定了软化接触模型的锐度。我们使用因子线性混合碰撞投影前后的网格点速度,带来边界周围的平滑过渡区以及更好的接触梯度。
实验
评估指标
首先为每个任务生成 5 个配置,从而生成 50 个不同的强化学习配置。我们计算归一化增量 IoU 分数来衡量状态是否达到目标,并使用软 IoU 来评估当前状态和目标之间的距离。首先提取网格质量张量,即所有网格的质量。每个非负值表示存储于网格点中的材料数量。令两个状态的 3D 质量张量分别为和。我们首先将每个张量除以它们的最大幅度以将其值归一化为:
然后,两种状态的软化 IoU 通过

进行计算。归一化增量 IoU 分数用于衡量在结束时 IoU 比初始状态时增加了多少。对于初始状态,结束时最后状态以及目标状态,归一化增量 IoU 分数定义为。对于每项任务,我们在 5 种配置上评估算法并计算代数平均分数。
评估强化学习
随后是在本文提出的任务上评估现有强化学习算法的性能。我们使用三种 SOTA 无模型强化学习算法:Soft Actor-Critic(SAC),Twin Delayed DDPG(TD3)和 Policy Proximal Optimization(PPO)。在每个配置上训练每个算法 10000 轮,每轮包含 50 个环境步骤。
图 3 展示了在每个场景上各种强化学习算法的归一化增量 IoU 分数。大多数强化学习算法可以在 Move 任务上学习到合理的策略。然而强化学习算法很难准确匹配目标形状,这会导致最终形状匹配中的一个小缺陷。我们注意到智能体在探索过程中经常释放物体,使得橡皮泥在重力作用下自由落体。然后智能体重新抓取橡皮泥变得具有挑战性,导致训练不稳定和令人不满意的结果。在 Rope 任务中,智能体可以将绳子推向柱子并获得部分奖励,但最终无法将绳子成功绕在柱子上。TripleMove 任务增加了操纵器和立体橡皮泥的数量,对强化学习算法带来了更大的困难,揭示了算法在扩展到高维任务方面的不足。在 Torus 任务中,算法性能似乎取决于初始策略。它们有时可以找到一个合适的方向按压操纵器,但有时因为操纵器从不接触橡皮泥而失败,从而导致显著的最终得分差异。PPO 的性能优于其他两个,在 RollingPin 任务中,SAC 和 PPO 智能体都能找到来回压平面团的策略,但 PPO 生成了更准确的形状,从而具有更高的归一化增量 IoU 分数。我们猜测此处的环境更倾向于 PPO 算法,而不依赖于 MLP 评价网络。这可能是因为 PPO 受益于 on-policy 样本,而 MPL 评价网络可能无法很好地捕捉详细的形状变化。
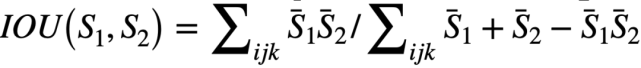
图 3 强化学习方法在 104 个 epoch 内获得的最终归一化增量 IoU 分数,低于 0 的分数被限制。橙色虚线表示理论上限。
在一些更难的任务中,例如需要智能体仔细处理 3D 旋转的 Chopsticks 任务,以及需要智能体规划复杂轨迹以绘制痕迹的 Writer 任务,被测试的算法很少能够在有限的时间内找到合理的解决方案。在 Assembly 任务中,所有智能体很容易陷入局部最小值。它们通常将球形橡皮泥移动到目的地附近,但未能将其抬起以得到理想的 IoU。我们期望精心设计的奖励塑造,更好的网络架构和细粒度的参数调整可能对环境有益。总而言之,可塑性以及软体的高自由度对强化学习算法提出了新的挑战。
评估轨迹优化
由于 PlasticineLab 内置可微物理引擎,我们可以使用基于梯度的优化为任务规划开环动作序列。在基于梯度的优化中,对于从状态开始的某个配置,初始化一个随机动作序列。模拟器将模拟整个轨迹,在每个时间步长累积奖励,并进行反向传播以计算所有动作的梯度。然后我们使用基于梯度的优化方法来最大化奖励总和。假设环境的所有信息已知。这种方法的目标不是找到可以在现实世界中执行的控制器。相反,我们希望可微物理可以有助于有效找到解决方案,并为其他控制或强化 / 模仿学习算法铺垫基础。
在图 4 中,我们通过绘制奖励曲线来证明可微物理的优化效率,并比较不同梯度下降变体的性能。我们测试 Adam 优化器(Adam)和带动量梯度下降(GD),使用软接触模型来计算梯度,将 Adam 优化器与硬接触模型(Adam-H)进行比较。对于每个优化器,我们适度为每个任务选择 0.1 或 0.01 的学习率来处理不同任务的不同奖励程度。值得注意的是,此处仅使用软接触模型来计算梯度并搜索解决方案。
我们在硬接触环境中评估所有解决方案。在图 4 中,额外绘制了强化学习算法的训练曲线,以证明基于梯度的优化的效率。结果表明,基于优化的方法可以在数十次迭代内找到具有挑战性任务的解决方案。Adam 在大多数任务中都优于 GD。这可能归因于 Adam 的自适应学习率缩放特性,它更适合高维物理过程的复杂损失面。在大多数任务中,硬接触模型(Adam-H)的表现不如软模型(Adam),这验证了软模型通常更容易优化的直觉。
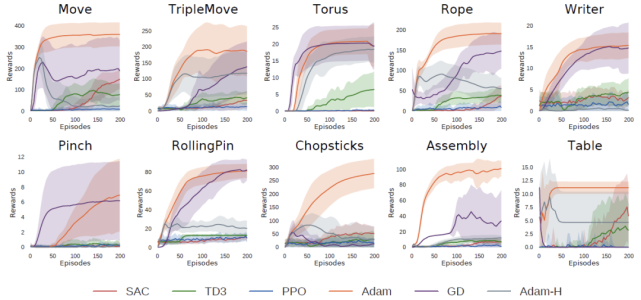
图 4 在每个任务中奖励及其方差随训练 episode 数量的变化。将奖励限制为大于 0 以便更好的说明。
表 1 列出了所有方法的归一化增量 IoU 分数以及标准方差。模型的全部知识为可微物理提供了获得更有价值结果的机会。用 Adam 梯度下降可以在 Rope 任务中找到移动绳子并绕上柱子的方法,在 Assembly 任务中跳过次优解,将球体放在盒子上方,并且在 Chopsticks 任务中能够用筷子夹起绳子。即使对于 Move 任务也能够更好地与目标形状对齐和更稳定的优化过程,获得更好的性能。
对于基于梯度的方法,某些任务仍然具有挑战性。在 TripleMove 任务中,优化器将粒子与最近目标形状的距离最小化,这通常会导致两个或三个橡皮泥聚集到同一个目标位置。对于没有探索能力的基于梯度的方法来说,跳出这种局部最小值并不容易。优化器在需要多阶段策略的任务上也会失败,例如 Pinch 和 Writer 任务。在 Pinch 任务中操纵器需要按下物体,松开它们,然后再次按下。然而在操纵器和橡皮泥第一次接触后,球形操纵器任何局部扰动都不会立即增加奖励,优化器最终停滞。我们还注意到基于梯度的方法对初始化非常敏感。实验将动作序列初始化为 0 左右,这在大多数环境中都具有良好的性能。

表 1 每种方法的平均归一化增量 IoU 分数和标准方差。Adam-H 表示使用 Adam 优化器对硬接触模型进行优化。基于强化学习的方法使用 10000 个 episode 进行训练,基于梯度的方法使用 200 个 episode 进行优化。
潜在研究问题
该环境为基于学习的软体操作提供了丰富的研究机遇。实验表明,微分物理学能够使基于梯度的轨迹优化算法以极快的速度解决简单的规划任务,因为梯度为改进策略提供了强大而清晰的指导。但是,如果任务涉及操纵器和橡皮泥之间的分离和重新连接,则梯度会消失。当无法使用基于局部扰动分析的基于梯度的优化时,我们可能会考虑那些允许多步探索并累积奖励的方法,例如随机搜索和强化学习。
因此,如何将可微物理与基于采样的方法相结合来解决软体操作规划问题,会非常有趣。除了规划问题之外,研究如何在这种环境中设计和学习有效的软体操纵控制器也非常有趣。实验结果表明控制器设计和优化仍有足够的改进空间,可能的方向包括为强化学习设计更好的奖励函数和研究合适的 3D 深度神经网络结构以捕获软体动力学。
第三个有趣的方向是将 PlasticineLab 中训练有素的策略转移到现实世界中。虽然这个问题在很大程度上未被探索,但我们相信我们的模拟器可以在各种方面提供帮助:
1. 如 Gaume 等人所示,MPM 仿真结果可以准确匹配现实世界。在未来的工作中,我们可能会使用模拟器为复杂任务规划一个高级轨迹,然后结合低级控制器来执行规划;
2. 该微分模拟器可以计算物理参数的梯度并优化参数以拟合数据,这可能有助于缩小 sim2real 差距;
3.PlasticineLab 还可以结合域随机化和其他 sim2real 方法。可以在该模拟器中自定义物理参数和图像渲染器以实现域随机化。我们希望该模拟器可以作为一个很好的工具来研究现实世界的软体操作问题。
最后,泛化性是一个重要的探索方向。该研究的平台支持过程生成,可以生成和模拟不同物体的各种配置,评估不同算法的通用性。PlasticineLab 也为设计丰富的目标条件任务提供了良好的平台。
相关阅读
-

云安全日报210527:Ubuntu配套LZ4解压缩软件发现执行任意代码漏洞,需要尽快升级
Ubuntu是一个以桌面应用为主的Linux操作系统。它是一个开放源代码的自由软件,提供了一个健壮、功能丰富的计算环境,既适合家庭使用又适用于商业环境。Ubuntu将为全球数百个公司提供商业支持。 ...
查看全文 -
云计算核心技术Docker教程:清理未使用的Docker对象
Docker采取了一种保守的方法来清理未使用的对象(通常称为“垃圾收集”),例如图像,容器,卷和网络:除非您明确要求Docker这样做,否则通常不会删除这些对象。这可能会导致Docker使用额外的磁盘空...
查看全文 -

消息称亚马逊、微软、谷歌正竞购波音公司10亿美元云合同
新浪科技讯 北京时间5月27日晚间消息,据报道,四位知情人士今日透露,亚马逊、微软和谷歌这三大云计算服务提供商,正在竞争波音公司(Boeing)价值10亿美元的云服务合同。 这些...
查看全文 -
亚马逊难逃反垄断惩罚?美国又有三个州加入调查
新浪科技讯 北京时间5月27日晚间消息,据报道,多位知情人士今日称,继加州、纽约州和华盛顿州之后,马萨诸塞州和宾夕法尼亚州的总检察长也加入到对亚马逊的反垄断调查中。 如今,越来越...
查看全文
您好!请登录